
Конструктор регулярных выражений zennoposter
Обновлено: 24.04.2024
В этой статье я хочу рассказать о регулярных выражениях. Для непосвященного пользователя они сложны для понимания, поэтому постараюсь максимально просто, с примерами, показать для чего и как они используются в Zennoposter. Надеюсь, данная статья будет полезна для всех!
Регулярные выражения достаточно широко используются в программе, а именно:
- Для поиска элементов;
- Во время парсинга данных с веб-сайтов или из файла;
- Для удобства обработки данных из различных источников (замене или удалению фрагментов текста);
- При установке разделителей в списках и таблицах;
- Многое другое.
Регулярное выражение - это язык поиска подстрок в тексте, основанный на использовании специальных символов и указателей. По сути это строка-образец, которая состоит из символов (статического текста) и спецсимволов (символов, обозначающих какие-то последовательности) и задаёт правило поиска подстроки в обрабатываемом тексте.
Для постройки регулярных выражений в программе есть специальный инструмент – «Конструктор регулярных выражений». В нём можно протестировать готовые выражения, а так же составить свои.

Возьмём текст и составим на его примере регулярное выражение так, чтобы получить домены сайтов:
a href="http://site.com">
a href="http://sitesite.com">
В Конструкторе есть раздельные поля - текст, который идет перед искомым (a href="), с которого начинается (http:), заканчивается искомый текст (.com), что идёт после него (">). В результате мы получим следующее регулярное выражение:
и список доменов в результатах тестирования.
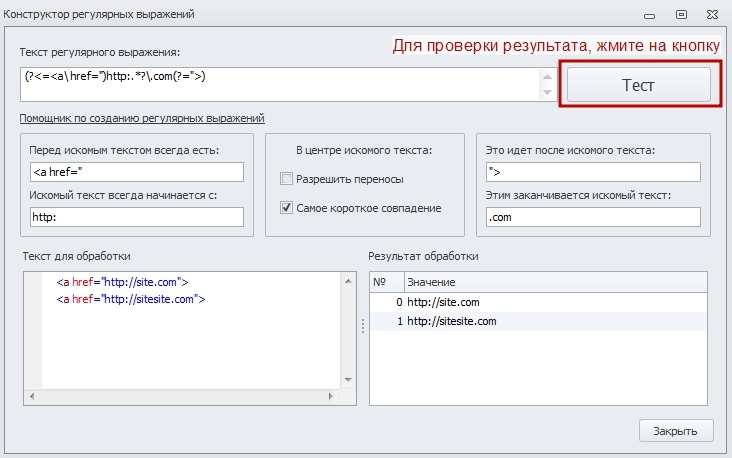
Так же в Конструкторе имеется два чекбокса:
1) Разрешить переносы - включает и выключает поиск по тексту с учетом переносов строк (при включении данной опции, регулярное выражение не ограничено поиском в пределах одной строки, а так же учитывает переносы строк);
2) Самое короткое совпадение - включает и выключает поиск самого короткого совпадения. При включении данной опции, в результатах мы получим самую короткую подстроку, соответствующую составленному выражению. При выключении, соответственно - самую длинную.
При заполнении этих полей, Ваш текст автоматически преобразуется и в поле "Текст регулярного выражения" будет предоставлено готовое выражение, которое можно использовать для поиска.
Конструктор регулярных выражений, который есть в программе Zennoposter, достаточно не плох, но не универсален. Он подходит для составления простых выражений, когда мы имеем точные совпадения в тексте - что идет перед или после текста, который нам нужно найти, чем он начинается или чем заканчивается. Иногда, полученный результат бывает не удовлетворительным - строк больше или меньше, чем нужно, или просто вместо искомого текста мы получаем разный мусор. В таких случаях необходимы более широкие знания и правка выражений, сформированных Конструктором, вручную.
Для того, чтобы правильно самостоятельно составить регулярные выражения, рассмотрим основные символы, определим в какой ситуации они могут использоваться.
«.» - любой символ, кроме переноса строки(\n);
«\d» - цифровой символ, т.е. любая цифра от 0 до 9;
«3» - цифровой диапазон - отличается от \d тем, что в данном виде есть возможность указать не любой цифровой символ, а используя диапазоны, например 3, который найдет только цифры 1, 2 и 3;
«\D» - не цифровой символ. Т.е. все символы - буквенные и пробелы, кроме цифр;
«\s» -все пробельные символы, которые могут включать в себя:
- пробел «\ »;
- новая страница «\f»;
- возврат каретки «\r»;
- новая строка «\n»;
- знак табуляции «\t»;
- знак вертикальной табуляции «\v»;
«\S» - не пробельный символ, т.е. все буквы, цифры и знаки. Всё, что не перечислено выше, как пробельные символы.
«\w» - буквенный или цифровой символ или знак подчёркивания.
«\W» - любой символ, кроме буквенного или цифрового символа или знака подчёркивания.
^ - начало строки;
$ - конец строки;
\b - граница слова;
\B - не граница слова.
К примеру, нам нужно проверить, содержит ли строка слово “Красный”, прописав в конструкторе «красный», мы можем получить так же и другие слова, в которые входит данное слово, такие как “прекрасный” и т.д. Что бы этого не происходило, необходимо прописать \bкрасный\b - таким образом, все слова, которые могут быть похожи на искомое учитываться не будут.
Не граница слова, соответственно, работает наоборот. К примеру, мы знаем, что слово должно заканчиваться на “жили”, но само слово “жили” нам не нужно, тогда мы прописываем \Bжили и получаем список слов с нужным нам окончанием - дорожили, выжили и т.д.
- ровно 5;
- от 1 до 5 включительно;
- от 1 и более;
? - ноль или одно, так же соответствует ;
* - ноль или более, так же соответствует ;
+ - Одно или более, так же соответствует .
Квантификаторы устанавливаются после символов, число повторений которых необходимо задать.
Возьмём для примера точку, которая обозначает любой символ, и составим регулярное выражение, которому будет соответствовать любая последовательность из 4 символов. Результат будет выглядеть таким образом: .
Так можно указать, что внутри искомого текста имеется установленное или неограниченное число повторений установленных символов, т.е.:
с.л - такое регулярное выражение найдёт такие слова, как стол, стул и т.д., но ему так же будет соответствовать строка, имеющая в середине пробелы, цифры и прочее.
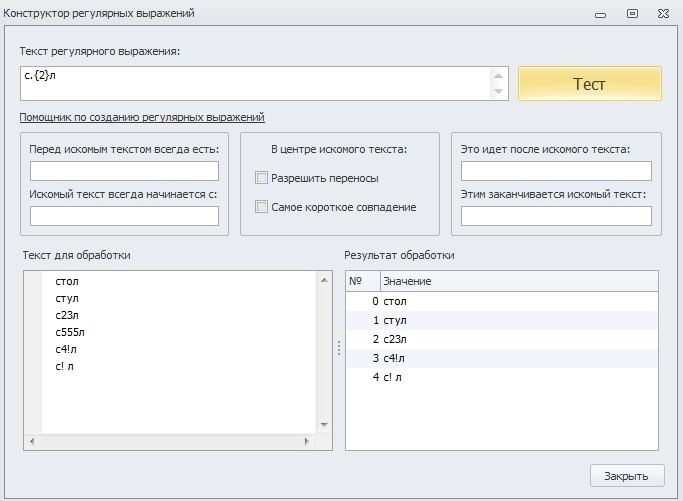
Для того, чтобы указать, что внутри будут только буквы, необходимо прописать таким образом:
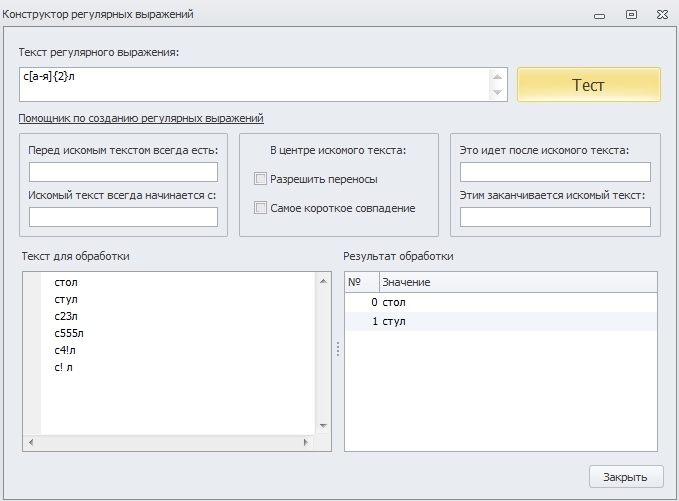
c[а-я]л
Так же можно задать определённую последовательность или набор символов, которые должны учитываться. Для этого используются квадратные скобки, внутри которых прописываются диапазоны, или наборы символов.
Для указания диапазонов используется тире между значениями. Для перечисления, символы просто прописываются в строку без каких либо разделителей.
[a-zA-Z1-5абв] - данная последовательность обозначает любую английскую букву в верхнем и нижнем регистре, числа от 1 до 5 включительно, а так же русские буквы а, б и в.
Регулярное выражение будет иметь такой вид:
с[тоу]л
Мы обозначаем, что после буквы “с” идут 2 любых символа, указанных в квадратных скобках и данная последовательность найдёт слова стол и стул, но ему так же будут соответствовать последовательности букв “суул”, “сутл” и прочие.
(?i) - включает нечувствительность выражения к регистру символов;
(?-i) - выключает нечувствительность выражения к регистру символов.
Используя данные модификаторы, мы можем указывать регулярному выражению, важен ли нам регистр символов при поиске совадений. Отключив регистр в начале регулярного выражения, мы его выключаем для всех последующих совпадений в строке.
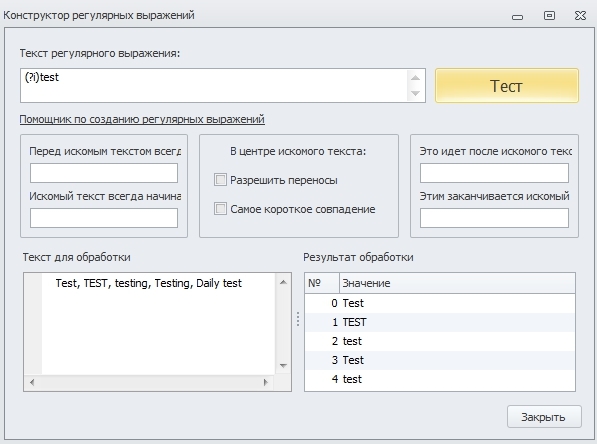
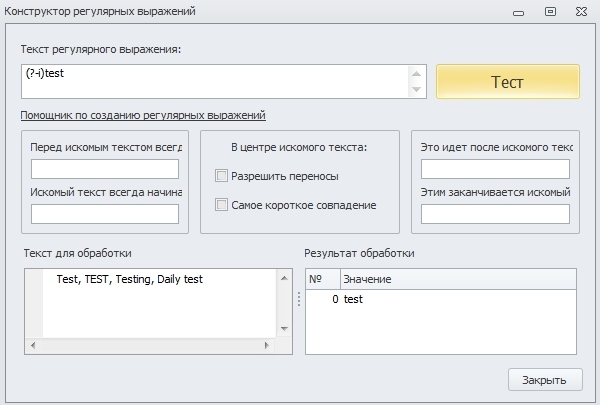
Так же бывают случаи, когда в одном месте регистр для нас не важен, а в другом важен.
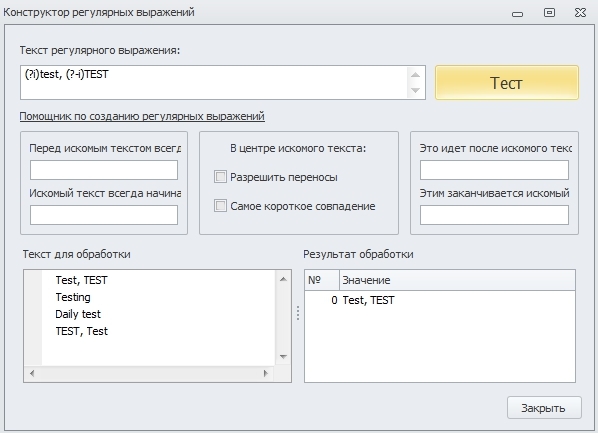
Данное регулярное выражение найдёт строку “Test, TEST”, т.к. у первой фразы включена нечувствительность к регистру и она находит все совпадения, но не найдёт “TEST, Test”, т.к. во второй фразе должно быть точное совпадение по регистру.
Модификаторы многострочного поиска:
(?m) - включает многострочный поиск
(?-m) - отключает многострочный поиск
Для того чтобы найти все строки, начинающиеся с не пробельного символа, подойдёт такое регулярное выражение:
(?m)^\S.*
Символы, которые должны экранироваться, для того, чтобы они учитывались в регулярном выражении как текст, а не как часть регулярного выражения (метасимволы):
При использовании данных символов в регулярном выражении, как части текста, они должны экранироваться знакоми \.
К примеру, если в тексте у вас должен находиться знак вопроса, он обозначается как \?
. - данному регулярному выражению соответствует последовательность от 5 до 10 любых символов, кроме переноса строки. Его можно использовать для обрезки текста до нужной длины, парсинга подстрок определенной длины, а так же для указания нужного количества неизвестного набора символов внутри текста.
а\d+а - в случаях, когда между искомым текстом, который известен, есть числа, состоящие из разного количества знаков. Данному регулярному выражению соответствует а1а, а23а, а459а и так далее.
а5а - данное регулярное выражение возьмет текст, который будет начинаться на “а” и содержать внутри от 2 до 4 цифр 2, 3, 4 или 5 и будет заканчиваться на “а”. К примеру, а354а или а52а
К примеру, вам необходимо взять url сайта из следующей строки id="123" a href="www.site.com">, где номер id всегда меняется, а просто в теге a href находятся и другие урлы, которые не нужны.
Тестер регулярных выражений выдаст нам такой вариант:
но ему будут соответствовать только строки, айди которых равен «123». Т.к. нам нужно указать, что вместо 123 может быть любая последовательность цифр, мы заменяем их на \d+ и получаем следующее регулярное выражение
которое получит все строки, содержащие любые айди.
Что касается самого короткого совпадения в регулярном выражении. Нужно понимать, что под самым коротким совпадением понимается часть текста, которая начинается и заканчивается по условию, заданному в регулярном выражении.
Почему поиск выдал нам не самое короткое совпадение? Происходит это потому, что регулярное выражение получило из текста первую часть, которая должна идти перед искомым текстом, т.е. “a href="”. Далее продолжило искать до тех пор, пока не нашло условие, по которому должна закончиться строка, т.е. “.ru”, после которого идёт ">
Для того, чтобы этого избежать, в данном случае можно использовать такую структуру регулярного выражения:
обозначить, что между частями искомого текста идёт непробельный символ, вместо любого символа, как было раньше
В случае же, если в части регулярного выражения может быть всё, что угодно - различной длины различный текст, или же он может вообще отсутствовать, можно в данном месте вставить последовательность «.*?»
Для указания того, что искомое значение начинается с новой строки и (или) заканчивается в конце строки, подойдёт такое регулярное выражение:
^строка$
Часто такое обозначение помогает построить правильное регулярное выражение для поиска элементов на вебстранице.
В случаях, если мы ищем элемент на разных сайтах, и он может отображаться с разным регистром, к примеру: Строка, СТРОКА, строка. С точки зрения машины эти три значения будут различными, и найдется только то, которое прописано с учетом регистра.
Если нужно подготовить регулярное выражение, которое найдет все эти совпадения, необходимо прописать
(?i)^строка$
т.е. мы отключаем у регулярного выражения чувствительность к регистру и дальше уже прописываем само регулярное выражение. В таком виде найдутся все совпадения, независимо от регистра.
Если необходимо взять текст с вебстраницы, почты или файла, то нужно учитывать, что начало строки, обозначаемое, как ^ - это только начало первой строки текста, а конец строки, обозначаемое как $ - это только конец последней строки.
Остальные строки в тексте имеют переносы, т.е. все эти строки заканчиваются символом возврата каретки (\r) а начинаются символом новой строки (\n).
Для того, чтобы обозначить, что регулярное выражение должно начинаться и заканчиваться в пределах одной строки, мы можем прописать условие ИЛИ, которое обозначается как вертикальный слеш - |
Регулярное выражение выглядит так:
(?i)(\n|^)строка(\r|$)
Так же можно дополнительно использовать модификатор многострочного поиска, который каждую строку считает, как новую:
(?im)^строка
В регулярном выражении можно указать, что именно искать, используя оператор ИЛИ следующим образом:
1|2 (что будет обозначать выбор 1 или 2.)
Таким образом, мы можем проверять на странице наличие сразу нескольких текстов.
К примеру, Вам необходимо проверить на странице фразы "Привет", "Спасибо за регистрацию", "Приветствуем Вас", мы можем объединить все эти данные в одно регулярное выражение следующим образом:
Привет|Cпасибо за регистрацию|Приветствуем Вас
При таком построении, проверка наличия текста на странице получит один из указанных вариантов.
В случае же, если знак “ИЛИ” необходимо использовать не для всего регулярного выражения, как показано выше, а только для его части, эта часть должна находиться внутри скобок. Например:
Что (Он|Она|Они) дела(е|ю)т\.
Данное регулярное выражение найдет фразы "Что Он делает." "Что Она делает." и "Что Они делают."
- найдет все теги в искомом тексте;
[\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9] - найдет все email;
(\d\.)\d:\d - получить айпи и порт;
Всем спасибо, кто осилил данную статью, надеюсь она была полезна прочитавшим её пользователям и пригодится еще многим.
Регулярные выражения - это шаблоны поиска подстроки в строке. Например, Вам в тексте нужно найти все слова, начинающиеся на букву 'a' или все слова не менее 4 букв и т.д. В ZennoPoster регулярные выражения помогут Вам, например, найти ссылку подтверждения в письме или текстовую каптчу на web странице. А если Вы будете писать парсер, то без регулярных выражений точно не обойдетесь.
Регулярные выражения на самом деле очень просты, нужно знать всего несколько команд-обозначений (а с нашим конструктором и это не обязательно).
Где в ZennoPoster используются регулярные выражения и для чего
Поиск подстроки в тексте файла.
Поиск письма подтверждения регистрации в ящике.
Поиск ссылки подтверждения регистрации в письме.
Поиск строк для удаления в списках.
Парсинг web страниц.
И ещё много всяких полезных применений.
Как быстро составить регулярное выражение в ZennoPoster
Для составления регулярных выражений Вы можете воспользоваться помощником - Конструктором регулярных выражений. Открыть его можно, нажав кнопку Тестер рег. выражений в меню расширенный редактор:
Или перейти из окна получить почту, нажав Здесь нет того, что мне нужно:
В левой области открывшегося окна вставляйте текст, который будете парсить. Чаще всего регулярное выражение для парсинга текста можно составить, используя начало или конец искомого текста, а так же текст, который стоит перед искомым текстом или после него. Для этого, под полем регулярного выражения Вы найдете четыре соответствующих поля, при добавлении туда соответствующего текста Вы увидите, как вверху собирается регулярное выражение.
В середине конструктора есть возможность выбрать, какая у искомого текста будет середина, если Вы выберите Разрешить переносы то в середине Вашего текста могут появиться переносы строк. Если же Вы не отметите этот чекбокс, то поиск будет в пределах одной строки. Так же, есть чекбокс, при включении его будет искаться Самое короткое совпадение - в результатах получится самая короткая подстрока, соответствующая составленному выражению. При выключении, соответственно - самая длинная.
Над полем регулярного выражения появилась кнопка История, здесь сохраняются полученные регулярные выражения, которые можно будет в дальнейшем использовать.
Программа позволяет использовать Групповые регулярные выражения и сохранить сразу несколько результатов одновременно. Далее результаты можно сохранить по группам в переменные с выбором номера совпадения, а так же в таблицу с возможностью исключения столбцов.
Обратите внимание
Регулярное выражение ищет столько подстрок, сколько есть в тексте. Если нужно взять какой-то конкретный номер совпадения, пользуйтесь диапазонами.
Основные команды
Также Вы можете самостоятельно попробовать составить регулярное выражение, воспользовавшись следующими советами:
Простейшее регулярное выражение можно записать так: abc
Этому выражению соответствует строка abc. Т.е. регулярное выражение, написанное текстом без команд ищет свой текст
Квадратные скобки ограничивают поиск теми символами, которые в них заключены: [abc]
В данном случае будет найдено подстрока состоящая всего из одной буквы a, b или c. Например, регулярное выражение [abc]d найдёт ad, bd или cd
Точка в регулярном выражении соответствует любому символу, кроме '\n'
Т.е., задав регулярное выражение '.', Вы найдёте любой символ кроме переноса. А задав выражение «…» - любую трехбуквенную подстроку. Регулярное выражение ab.. найдёт Вам в тексте подстроки из 4-х букв начинающиеся на ab
В регулярном выражении можно использовать символ '|', действующий как оператор OR (или)
К примеру, следующее регулярное выражение ищет в строке подстроки ru, com или net: (ru|com|net)
Для исключения последовательности символов из поиска перед ней ставится символ ^, например:
[^аbcd] (или [^а-d]) - соответствует любому символу, кроме a,b,c,d. Обратите внимание, что символ ^ находится внутри квадратных скобок, так как только в этом случае он имеет значение не
Регулярное выражение можно уточнить при помощи символов +, ?, *, например:
a+ - одна или более буква a (строки aaaa и aa соответствуют этому выражению, а строка hello или a - нет)
a? - ноль или одна буква а. Например, регулярным выражением 123a+ мы ищем любую подстроку, которая начинается на 123, и, возможно, заканчивается на a (или нет)
a* - ноль или более а
Можно указать количество искомых символов, или диапазон, например:
xy - соответствует строке, в которой за x следует два y
xy - соответствует строке, в которой за x следует не менее двух y (может быть и больше)
xy - соответствует строке, в которой за x следует от двух до шести y
Для указания количества вхождений не одного символа, а их последовательности, используются круглые скобки:
x(yz) - соответствует строке, в которой за x следует от двух до шести последовательностей yz
x(yz)* - соответствует строке, в которой за x следует ноль и более последовательностей yz
В регулярном выражении можно указать, должно ли конкретное подвыражение встречаться в начале, в конце строки или и в начале и в конце строки. Символ ^ соответствует началу строки, знак доллара $ соответствует концу строки:
^xy - соответствует любой строке, начинающейся с xy. Обратите внимание, что в этом случае символ ^ ставится за пределами выражения в скобках, к примеру ^[a-z]
xy$ - соответствует любой строке, заканчивающейся на xy
В тех случаях, когда нужно сопоставить выражение строке, в которой встречаются спецсимволы, такие как $, ^, и т. д., перед ними ставится символ обратной косой черты «\».
Например, для того, чтобы найти в строке символ $, в регулярном выражении нужно написать \$
Еще несколько спец. символов, которые могут понадобиться:
\w - слово (цифра или буква)
\W - не слово (не цифра и не буква)
\d - десятичная цифра
\D - не десятичная цифра
\s - пустое место (пробел, \f, \n, \r, \t, \v)
\S - не пустое место (не пробел, не \f, не \n, не \r, не \t, не \v)
Регулярные выражения - это своеобразный фильтр для поиска текстовых строк, соответствующий требуемым условиям. Встроенный конструктор регулярных выражений позволит быстро создавать правила, не вникая во все тонкости их составления.
Где используются регулярные выражения?
Извлечение информации со страниц сайта
Фильтрация данных в списках, таблицах
Поиск письма и\или ссылки подтверждения регистрации;
Поиск конкретного фрагмента в тексте
Поиск строк для удаления в списках;
И множество других полезных применений
Как быстро составить регулярное выражение в ZennoPoster?
Для их составления вы можете воспользоваться помощником - Тестером регулярных выражений. Его можно найти в меню Инструменты → Тестер рег. выражений
Окно Тестера регулярных выражений
Вкладки
Вы можете одновременно работать над несколькими регулярными выражениям в разных вкладках. В качестве имени вкладки используется текст регулярного выражения.
История
Сюда сохраняются все выражения, которые Вы проверяли с помощью кнопки Тест.
Текст регулярного выражения
Тут будет находиться текст регулярного выражения. Вы можете редактировать текст в этом поле.
При внесении изменений в поля и чекбоксы из группы Помощник по созданию регулярных выражений все правки, которые Вы вносили в текст выражения вручную, будут утеряны!
Кнопка Тест
После нажатия выражение из поля Текст регулярного выражения применится к Текст для обработки. Что из этого получилось можно найти в Результат обработки.
Перед искомым текстом всегда есть, Это идёт после искомого текста
Этот текст ищется, но не будет включён в результат работы выражения.
Искомый текст всегда начинается с, Этим заканчивается искомый текст
Данный текст включается в результат работы.
Разрешить переносы
Включение\отключение многострочного поиска.
Самое короткое совпадение
При включении данной опции, в результатах мы получим самую короткую подстроку, соответствующую составленному выражению.
Текст для обработки
В это поле нужно ввести текст, по которому будет производиться поиск текста.
Данные в это поле можно внести прямо из переменной проекта: ПКМ=>Установить значение из переменной.
Возможность установить значение из переменной добавлена в ZennoPoster 7.4.0.0
В выпадающем списке будут отображены переменные текущего активного проекта.
Показывать специальные символы
Стоит ли отображать переносы строки, табы (и некоторые другие символы) в виде специальных символов?
Выключено
Включено
Результат обработки
Вкладка Совпадения
Здесь будет отображён результат применения регулярного выражения к тексту.
Вкладка Группы
Сюда попадут результаты работы в случае применения Групповых регулярных выражений. Пример таких выражений можно найти в описании экшена Обработка текст => Regex => В переменные.
Пример использования
Давайте разберём на примере конкретной и часто встречающейся задачи – парсинг ссылок. Допустим, мы получили HTML какого-то DIVа или весь DOM страницы и нам нужно спарсить все ссылки с этого кода и сохранить их в список.
Вставляем в поле наш исходный код в котором будем искать ссылки (быстро вставить код текущей активной вкладки в Тестер можно с помощью окна Просмотр текста страницы ).
Укажем подстроку, которая обычно идет перед ссылкой, а именно тег a href=” .
Добавим кавычки, которыми закрывается строка ссылки. Не забываем галочку «Самое короткое совпадение», ведь нам нужно собрать строку только между двумя крайними кавычками.
Нажмём кнопку «Тест» и в поле «Результат обработки» появится нужный нам список из ссылок (если есть совпадения). Если получилось что-то не то, попробуйте изменить условия поиска.
Можем скопировать готовое регулярное выражение и применить его в своём шаблоне. Например, в действии Обработка текста → Regex
Регулярное выражение ищет столько подстрок, сколько есть в тексте. Если нужно взять какой-то конкретный номер совпадения, пользуйтесь диапазонами.
Символы со специальным значением
Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов [ ] \ / ^ $ . | ? * + ( ) < >, которые могут быть экранированы символом \ (обратная косая черта) для представления самих себя в качестве символов текста. То есть простейшее регулярное выражение можно записать так: abc , которому будет соответствовать строка abc.
Регулярные выражения помогают при обработке текста внутри программы ZennoPoster или любой другой, которая поддерживает данный синтаксис и структуру (Notepad++).
Кроме того, при помощи «регулярок» можно «вытащить» из огромного куска текстовых данных, например, ТОЛЬКО телефоны, ТОЛЬКО email или любые другие данные, а затем софт ZennoPoster положит их красиво в таблицу формата CSV или XLSX.

Помимо очевидных плюсов, автоматизации действий и сокращения времени на поиск нужных элементов на страницах сайта или обычного текста, вы получаете полностью готовый комплект, которым удобно пользоваться, а также софт постоянно совершенствуется (к примеру, сейчас уже выпущена 7 версия продукта, где можно указать темную и светлую тему в настройках). Но, вернемся к регулярным выражениям — они созданы для облегчения нахождения нужного куска текста, формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов (символов-джокеров, англ. wildcard characters). При этом, не все такие выражения подходят в каждой программе, поэтому нужно читать руководство пользователя прежде чем начнете поиск каких-либо данных.
ZennoPoster хорош тем, что у вас под рукой всегда (при нажатии клавиши F3 внутри софта) лежит инструмент, который предоставляет тестирование регулярных выражений, и вы видите что получается на выходе, потому не приходится тысячу раз вводить различные варианты «регулярок». Как по мне, это лучший вариант, когда вы только начинаете знакомиться с такими сложными схемами взаимодействия текста и вывода данных.
Что умеют делать регулярные выражения?
Сами по себе, конечно, ничего не умеют делать, а вот в комплексе с программным обеспечением — очень даже много. Например, частой задачей является удаление тегов HTML из текста, скопированного откуда-то (это могут быть таблицы или обычные параграфы). Рассмотрим для начала софт Notepad++, где можно менять данные в тексте как через обычный поиск, так и через поиск «регулярок».
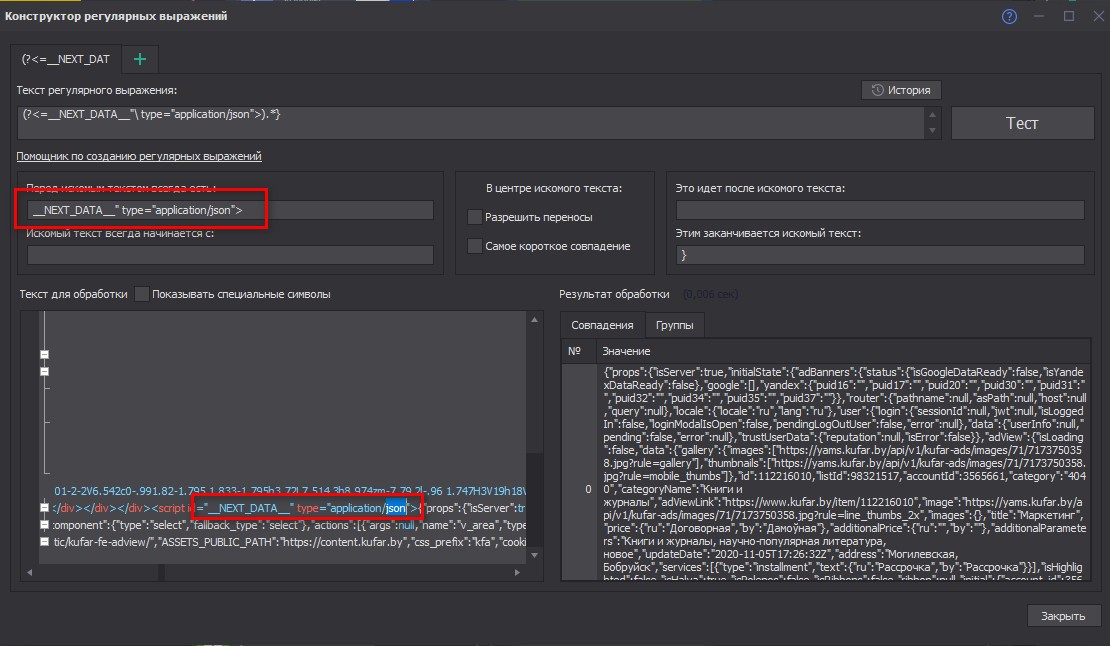
ZennoPoster. Рассмотрим с вами пример, когда из кода страницы берется JSON формат (если он, конечно, присутствует на странице), т.к. внутренняя функция парсинга данного формата позволяет работать с данными более гибко и быстрее, чем с обычным текстом.

Итак, копируем текст, нажав на кнопки CTRL + U (в браузере Chrome), далее вставляем его внутри программы (клавиша F3 в ЗенноПостере и функционал «Конструктор регулярных выражений»). Теперь смотрим как это работает… Находим через CTRL + F для начала «JSON», собственно конец и начало.




Берем блок с обработкой текста, вставляем полученное ранее значение в поле данных и выбираем их парсинг. После этого у вас должны появиться структурированные ячейки, где указаны для каждой формулы собственные наименования. Что это нам дает в итоге? Все очень просто — у нас с вами структурированные числа, строки и т.п., которые можно одним действием поместить в таблицу, SQL и т.д., не вычисляя отдельные элементы на странице и не привязываясь к идентификаторам объектов на них. Т.е. к примеру разработчик сайта решил поменять стиль сайта или поменять классы у DIV, то поиск стандартным путем становится затруднительным (хотя в ZennoPoster есть и новая функция — поиск элемента на странице с помощью xpath, но как показывает практика, такой подход не всегда эффективен).

Вернемся к регуляркам
Где конкретно можно использовать такие выражения? Например, удобно выбрать ссылку в письме, если вы не знаете ее, но уверены, что она должна вести на определенную страницу или начинаться с нужного аlреса url — в этом случае поможет поиск через знакомую опцию «Конструктор регулярных выражений», а затем на основе полученного выражения уже можно вставить его в блок «Получить почту».

Рассмотрим другие примеры:
- получение телефонов из кучи неразобранного текста;
- получение электронных адресов после парсинга страниц;
- взять списки имен, фамилий, дат рождений и прочих контактных данных путем парсинга JSON формата или HTML;
- использование API, SMS и других полезных функций при обработке больших объемов данных.

Больше — лучше!
Это еще не все! Возможности Зеннопостера удивляют, т.к. софт может сделать практически что угодно, а что касается «регулярок», то у вас в запасе есть интересная опция «Групповые регулярные выражения». С помощью нее вы будете разделять по группам текстовые данные и любые другие, которые разделены между собой определенными символами. Более подробно об этой замечательной функции можно прочитать тут.
Добавьте пожалуйста конструктор регулярных выражений как в Zennoposter.
Или же парсинг данных как в Private Keeper, Openbullet.
Т.е парсит примерно так: Вставляю начальную строку ctf_token=" и бас сам определяет что в конце должна быть "
Это очень удобно.

Добавьте пожалуйста конструктор регулярных выражений как в Zennoposter.
Или же парсинг данных как в Private Keeper, Openbullet.
Т.е парсит примерно так: Вставляю начальную строку ctf_token=" и бас сам определяет что в конце должна быть "
Это очень удобно.

Он очень неудобный
Используйте любой удобный. В чем проблема-то? Регулярные выражения относятся не только к этим программам.

Список - это набор данных каждый с новой строки
Запросы функционала • • Turutur

В Менеджере данных ---- добавить импорт в Xls.
Запросы функционала • • DEDOV

Также проверить импорт в CVS там явно проблемы,русский текст не распознает,не понимает разделения. Попробовал, не могу повторить. У меня работает и русский текст и пробелы. Приложите файл, который у вас не работает. Вот мой test.csv
Парсинг
Запросы функционала • • lodritu2psa
Визуализация построения или конструктор для скриптов
Запросы функционала • • Turutur
@Turutur В БАС действия идут по порядку. Те действия, которые прерывают порядок: вызов функций, завершение потока, выделены красным.

Сохранение профиля, либо запись данных в базу
Запросы функционала • • blackhacker

Формат данных для локальной базы данных
Запросы функционала • • mansory333
@Fox ахаха, Я тупанул) Так у меня есть сервер на mariadb, даже не подумал об этом. Спасибо вам большое, Я уже хотел json из csv костылить)
Читайте также: