
Как записать на игрушку свой голос
Обновлено: 15.05.2024
найти немогу.
В самой игрушке коробочка на которую нажимаешь и она поет, а вот как записать туда свою мелодию?
Как записывать голосовое послание в домашних условиях?
Для того, чтобы создать голосовые приглашения, вы можете выбрать профессионального диктора или же записать его своими голосами. Преимущества записи своими голосами очевидны:
Вы, лично, обращаетесь к человеку, приглашая его на торжественное мероприятие.
Ваш голос останется прежним, даже через 50 лет спустя.
Вы можете подъехать в нашу звукозаписывающую студию в Санкт-Петербурге, где на качественном оборудовании, в сопровождении специалиста НЛП, вы войдете в состояние восторга, в котором и создадите свою “голосовую бомбу”.
Если вы выбрали наиболее всё же простой способ создания голосового приглашения на свадьбу. То ознакомьтесь с приведенной ниже информацией.
Запись голосового приглашения на свадьбу.
Весь процесс, состоит из 2х основных частей:
Настройка оборудования для записи.
Самонастройка и запись.
Также обратите внимание на место записи. Стены, мебель и пр. предметы многократно отражают звук, создавая резонанс, которой, к сожалению плохо влияет на качество самой записи. Рекомендуем небольшие помещения, где много предметов различных форм и по возможности имеются ковры, т. к. они являются отличными звуко-поглотителями.
Самонастройка: Для того, чтобы человеку передалось ВАУ, т. е. ваши радостные чувства и эмоции, вы должны ощущать их сами – во время записи! Не спешите. Сначала подготовьте текст, Текст должен состоять из 2 х частей, основной, где “приглашаем вас … туда-то и тогда-то” и имена, например “Здравствуйте Иван Иванович” или “Дорогая наша Марина Борисовна” и т. д . Подготовьте тексты на бумаге, несколько раз прочтите, желательно с улыбкой и перед зеркалом. Когда поймете, что само содержание вам нравиться, звучит гладко и красиво – приступайте к записи.
Если у вас или у вашего будущего партнёра по жизни плохое воображение и он/она не может представить те чувства и то состояние, которое будет у вас во время свадьбы, используйте другой приём. Для этого, вам нужно не фантазировать, а вспомнить своё прошлое, а именно самый счастливый момент вашей жизни. Когда, где и как это была, а главное – что вы чувствовали в этот момент? Это может быть напряжение, потепление, мурашки, холод и др. физические ощущения в вашем теле. Именно их и нужно вам воспроизвести.

Не секрет, что имея бюджет на вычисления в единицы или десятки миллионов долларов, напоказ достичь можно многого. Но реальность как правило оказывается более сложной и прозаической.
Вопреки этому тренду, в этой статье мы постараемся на пальцах и близко к народу:
- На реальных примерах показать возможности генерации голоса на малом числе данных или на данных с неидеальным качеством;
- Немного порассуждать на тему цифровых памятников (это чем-то похоже на интерактивные или трехмерные фотографии), сделанных из голоса человека;
- Также немного порассуждать на тему того, какую объективную опасность это представляет для общества;
И также мы конечно поделимся новостями нашего публичного синтеза речи.
Границы возможного
Хорошая актуальная иллюстрация на злобу дня — маркетинговые материалы OpenAI против более менее вменяемых попыток повторения от комьюнити:

Но если вернуться к нашей реальности, то в современной парадигме машинное обучение — это скорее сжатие данных. Фотографии уже как более века не являются диковинкой (и в современном понимании тоже являются сжатыми данными, тот же JPEG — это максимально популярный пример). Трехмерные фотографии (голограммы) — на самом деле в самом примитивном исполнении — тоже есть везде (стикеры, магнитики и вкладыши). Фотографии с картой "глубины" до недавнего времени требовали специального оборудования. Но сейчас появляются смартфоны с такими камерами и ее восстанавливают (точнее галлюцинируют) те же нейросети.
В самом-самом эпизоде сериала Черное Зеркало "White Christmas" четко прослеживается идея цифрового посмертия и сохранения каких-то цифровых артефактов.
Сейчас такими артефактами обычно являются фотографии, аудио и видео. Но как правило, такие артефакты не являются интерактивными. Появляются алгоритмы для анимации лиц и / или фото. Но что если рассмотреть сам голос непосредственно как некоторую "открытку" или привет из прошлого от некоего человека? Вы не можете заставить такую открытку саму говорить то, что бы говорил реальный человек (говорящие про "мышление" нейросетей люди просто лукавят), но голос может быть узнаваем или даже неотличим от реального при каких-то условиях.
В принципе "успехи" так называемых больших языковых моделей (LLM) могут сделать примеры из Черного Зеркала с созданием полных цифровых аватаров людей чем-то извращенно похожим на реальность. Но при детальном общении они будут рассыпаться буквально через 1-2 фразы и в лучшем случае пока будут примером грубой "китайской комнаты", которая сделала лишь один маленький шаг от бредогенераторов. Но голос, если вынести за скобки огромную палитру человеческих эмоций и интонаций, сохранить в принципе можно уже более менее точно и неотличимо.
Отдельный философский вопрос возникает: вот я сделал "копию" голоса близкого человека, но что будет с этим файлом через 50 лет? С одной стороны веса нейросети так и останутся матрицами, но все теперешнее окружение (например PyTorch) скорее всего уже уйдет в небытие. Возникает некая аналогия с тем, что HiFi электроника из 70х является условно самодостаточной (если есть розетка 220V и заменить резиновые ремни), а современные "подписочные сервисы" не будут найдены археологами. По этой причине интересно будет посмотреть на маркетинговые материалы инвестиционных стартапов, которые рано или поздно возьмутся за такое дело.
Будут ли они предлагать саппорт на 1 год, 5 лет, 50 лет, или будут как обычно все умалчивать и потом тихо пропадать? Логичной кажется конечно генерация большого количества каких-то неслучайных (?) фраз и просто хранение их тупо на диске или в какой-то физической оболочке. Например, если человек записал книгу или статью, можно ее озвучить и показывать потомкам.
Критерии успеха при создании голоса
В течение последних нескольких месяцев мы сделали несколько пробных и не очень проектов и выделили основные критерии, которые влияют на качество синтезированного аудио (сначала самые важные):
- Качество и количество аудио;
- Качество и свойства самого голоса, четкая дикция, консистентность (мы не умеем сохранять всю палитру эмоций);
- Соответствие канонам произношения и соответствие фонем их типичному произношению, точность произнесенного написанному (да, внезапно);
- Похожесть на существующих спикеров и наличие базы "идеальных" спикеров на нужном языке;
В прошлой статье мы приводили примеры запуска похожих голосов и даже более менее похожих голосов на разных языках "с холодного старта" и "с теплого старта" (пример чего-то относительно похожего в литературе). В этот раз мы уже провели сильно больше экспериментов и у нас сложилась некоторая более связная картинка мира.
В прошлых статьях мы подметили, что ударение сильно повышает качество синтеза для русского языка, а фонемы как будто не очень. Поигравшись с языками народов СНГ, также мы обратили внимание на сильную "фонетическость" записи некоторых языков (особенно на кириллице, когда письменный язык делали лингвисты не так давно). В каком-то смысле это также применимо к немецкому и испанскому.
Картинка сложилась, когда мы пробовали тренировать модель "с теплого старта", когда целевой спикер говорит по-английски, а спикер-донор — по-русски. Предсказуемо, так просто не работало даже с теплого старта при прочих равных и похожих голосах. При более детальном рассмотрении оказалось, что у русского, испанского и немецкого языков очень похож набор фонем, в отличие от английского.
Чтобы не растекаться мыслью по древу, сведу все итоги по абстрактным типам экспериментов в одну несколько упрощенную таблицу:
| Номер | Старт | Качество / дикция / шум | Количество аудио | Фонетика | Качество |
|---|---|---|---|---|---|
| Яндекс | Холодный | Диктор с "войс-коучем" | 40 часов | В примерах был русский | 4-5+ |
| (1) | Холодный | Хорошее, диктор | 3+ часов (лучше 5) | Любой язык | 4-5 |
| (2) | Теплый | Хорошее, диктор, нет шума | От 5-15 минут | Тот же язык и диалект | ~4 |
| (3) | Теплый | Среднее, нет дикции, мало шума | От 5-15 минут | То же, но голос похож | 4-, артефакты |
| (4) | Теплый | Среднее, нет дикции, мало шума | 20-30 минут | То же | 4- |
| (5) | Теплый | Голос В.И. Ленина | 15-20 минут | То же | 3- |
| (6) | Теплый | Хорошее, голос диктора | 3+ часов | Другой язык, похожая фонетика | 4 |
| (7) | Теплый | Среднее, дикция "плавает" | 15-20 минут | Другой язык, не похожая фонетика | не работает |
| (8) | Теплый | Среднее, дикция "плавает" | 15 минут | Тот же язык, разный акцент | 4- |
| (9) | Холодный | Хорошее, голос 1 диктора | 15 минут | Любой язык | не работает |
| (10) | Холодный | Хорошее, много дикторов | 10+ часов | Любой язык, дикторы похожи | 4+ |
Что интересно, в случае (6) пол, язык и похожесть голоса особой роли не играют, если язык похожий по звучанию. Если построить ментальную модель происходящего, то усилия дикторов можно экономить имея в загашнике много дикторов даже не с похожими голосами, а с похожими соответствиями между произносимыми звуками и "фонемами", которые с листа читает диктор. Простым языком — похожий диалект / акцент / набор часто произносимых фонем.
Ну то есть грубо говоря, если вы хотите сделать максимально качественную модель для людей, говорящих на индийских языках или на английском с индийским акцентом на малом числе данных, вам надо иметь данные не с идеальным британским произношением, а с произношением похожим на целевой домен. В ретроспективе это кажется очевидным, но в процессе постановки экспериментов гипотез была тонна.
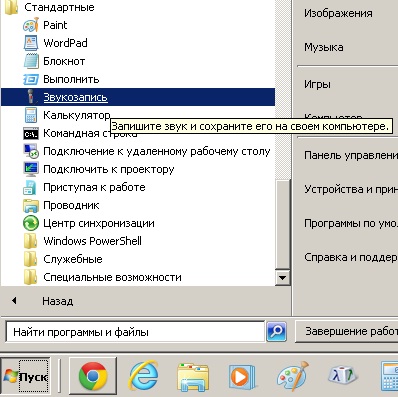
В этой статье я расскажу Вам, каким образом можно наложить голос на звук, не используя cпециализированное программное обеспечение (в том числе драйверов виртуальных устройств и т.п.). То есть, обойтись средствами вашей операционной системы (будем рассматривать Windows 7).
В Windows есть встроенная функция звукозаписи, так и называется Звукозапись, вызывается из меню Пуск / Все программы / Стандартные / Звукозапись. Интерфейс у неё, конечно, минимальный — есть одна кнопка [Начать запись] и пара индикаторов — времени (длительность записи) и уровня громкости.

По нажатию на [Начать запись] начинается процесс записи звука, на этой же кнопке возникает надпись [Остановить запись], при нажатии на которую, система спрашивает путь, по которому будет сохранён файл, содержащий произведённую звукозапись.
Вот Вы уже можете записать свой голос. А каким образом добавить к своему голосу звуковое (или музыкальное) сопровождение? К примеру, в проигрывателе Windows Media Вы запустили инструментальную музыку (так называемую минусовку) — прекрасно слышите её в наушниках или через колонки, а сами поёте в микрофон. Записываете с помощью «Звукозаписи», а потом, слушая, сохранённый файл — понимаете, что записался только Ваш голос. Без музыки. Что делать?
Для начала, нужно узнать есть ли у Вашей звуковой карты такая полезная возможность, как выбор в качестве источника для записи суммарного звукового потока, выводящегося на колонки или наушники. Обычно эта функция называется What U Hear, или ещё виртуальный микшер звуковой карты. Посмотреть это очень просто — правой кнопкой мыши нажмите на картинку динамика в правом нижнем углу и выберите пункт меню «Записывающие устройства». У Вас откроется окно «Звук» на закладке «Запись». Найдите в списке устройств элемент с названием What U Hear (Что Вы Слышите), Stereo Mix (Стерео Микшер), Mixer, Микшер (иногда Миксер) или что-то похожее. К примеру, на моём компьютере устройство называется «Стерео микшер».
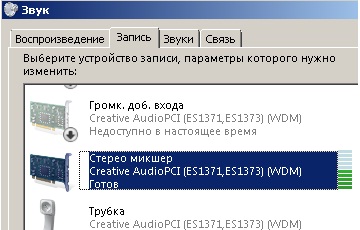
По-умолчанию это устройство бывает выключено, и тогда его может быть не видно в списке, хотя оно есть. В этом случан нажмите на правую кнопку мыши на списке устройств для записи, и поставьте галочки «Показать отключенные устройства» и «Показать отсоединенные устройства» в открывшемся меню, и включите (также, правой кнопкой мыши на пункте «Включить») его. Чтобы понять, что это действительно «оно» — запустите воспроизведение какого-нибудь звукового файла, например, в проигрывателе Windows Media, после чего понаблюдайте за списком устройств записи. Справа от What U Hear увидите индикатор с меняющимся уровнем громкости. Если не нашли эту функцию — пропускайте следующий параграф и читайте сразу У звуковой карты нет «What U Hear».
У звуковой карты есть «What U Hear»
- Сделайте устройство «What U Hear» как записывающее по-умолчанию (правой кнопкой мыши на списке закладки «Запись»)
- Изолируйте микрофон от динамиков. К примеру, если у вас ноутбук со встроенными микрофоном и динамиками, то если вы сделаете что написано в следующем пункте, то из-за обратной связи ничего кроме шума и свиста вы не услышите. Надо каким-то образом сделать так, чтобы до микрофона не доходил звук из динамиков. Лучший способ — подключить наушники с микрофоном, хотя можно использовать отдельные, плотно прилегающие наушники.
- Выберите из списка записывающих устройств микрофон, откройте его свойства (правой кнопкой мыши), в окне свойств микрофона выберите закладку Прослушать и поставьте галочку «Прослушивать с данного устройства». Нажмите [Применить] и скажите что-нибудь в микрофон, если возникнет самоподдерживающийся шум/свист — отключите галочку «Прослушивать с данного устройства», после чего внимательно прочитайте предыдущий пункт и выполните содержащиеся в нём рекомендации.
Рекомендую сначала убрать усиление микрофона на закладке «Уровни» и поставить половинную громкость там же. Если звук будет записываться в неудовлетворительном качестве, то попробуйте менять эти настройки.
У звуковой карты нет «What U Hear»
Здесь вам не обойтись без покупки 3.5 мм аудио-кабеля «папа-папа» и, возможно, 3.5 мм аудио-разветвителя (для разветвителя представлены два возможных варианта внешнего вида):


Характеристики звукового модуля
- Микросхема ISD1820;
- Напряжение питания: 3…5 В;
- Встроенный микрофон;
- Может записывать до 10 секунд аудиозаписи;
- Высокое качество аудиозаписи;
- Поддерживает единоразовое и циклическое воспроизведение;
- Модуль может управляться микроконтроллером;
- Размеры устройства: 54 х 38 х 18 мм;
- Цена примерно 150 рублей.
Схема электрическая включения ISD1820

- Перемычка SW1 переводится в замкнутое положение, для сквозного прохождения звука от микрофона если используется внешний усилитель.
- Перемычка SW2 переводится в замкнутое положение, если необходимо бесконечное циклическое воспроизведение записи.
Мощности достаточно для подключения динамика до 1 ватта. Звук при этом средней громкости. Субъективно маловато высоких, но в принципе чёткость на уровне. С самостоятельным подключением справится даже чайник, ведь всё что требуется от человека - подать питание. А остальное уже собрано на плате: микрофон, кнопки, светодиод и так далее. Даже динамичек через разъём подключен.


Если же вы упорно желаете сэкономить и спаять девайс своими руками - вот архив с платой. От аккумулятора оно тянет 0,2 мА при молчании и 40 мА на проигрывании звука. Верхняя граница напряжения питания не менее 8 вольт (случайно подал и ничего не сгорело - работало).
Сферы использования модуля
Применение самое широкое, тем более питается блок от стандартной литий-ионной батареи или аккумулятора - дверной звонок с возможностью установить любой эффект (хоть голос любимой тёщи или мелодию из Звёздных Воинов), озвучивание событий в устройствах сигнализаций, автоматики, систем контроля. Я, например, встроил плату в самодельный супер-бластер, про который рассказывал тут. Ребёнок очень и очень доволен - побегал, пострелял, надоело - поднёс его к колонке АС и нажав "запись" установил в память микросхемы другой эффект (лазер, автомат, пушка, шокер и т. д.) найденный в интернете или фильме.



Не сомневаюсь, что в продаже есть (или появятся потом) и другие аналогичные модули, но и этого хватает с головой, разве что время записи чуть продлить.

Приводятся основные сведения о планарных предохранителях, включая их технические характеристики и применение.

Обзор типовой схемы проигрывателя MP3, USB, SD, FM на базе чипа AC6905A.

Элементы и батареи Li-Ion, Li-Po и LiFePO4 - особенности каждого типа литиевых аккумуляторов и основные различия.

Что такое изолятор и чем он отличается от токопроводящего материала. Занимательная теория радиоэлектроники.
Модуль уже прикрутил.
Тебе нужно обклеить его самоклейкой и чтоб было типа "пламя".
Так что это чудо умеет? и как заряжать?
До обклейки ещё не дошло - но как будет время займусь. Умеет светить ярким светодиодом как фонарь, пускать молнию шокером, светить лазерным целеуказателем, воспроизводить любой звук, а сейчас сижу выбираю оптический прицел - вцеплю сверху. Думаю взять что-то типа 3-7Х28 за 800 руб.
Крышку кабель канала открыть, крокодилы на провода от Imax6 кинуть - так и зарядить. Но там такая ёмкость АКБ, что это не скоро понадобится.

ГЛАВНОЕ!
Записать свой голос или голоса своих друзей и близких,
а также голос ребенка в домашних условиях вполне РЕАЛЬНО!
Знаете ли вы, что 90% людей очень непривычно слышать СВОЙ ГОЛОС в записи,
НО тем, кому вы будете дарить ВАШ ПОДАРОК - этот голос знаком и приятен!
Пишите здесь свои вопросы, а также делитесь опытом!
Для того чтобы сделать качественную аудио запись вам нужно пройти 3 шага:
Шаг 1. – Подготовка.
Если у вас еще нет – ОБЯЗАТЕЛЬНО составьте сценарий записи. Запишите текст на бумаге и тщательность прорепетируйте. Рекомендуем сделать это перед зеркалом, т.к. вы сможете следить за своими эмоциями. ГЛАВНОЕ. – чтобы на вашем лице была УЛЫБКА. ))).
Рекомендуем использовать ОДНОВРЕМЕННО 2два источника записи записи звука: телефон, диктофон, другой компьютер. Это позволит выбрать максимально качественную запись. И не беспокойтесь о лишних паузах и звуках, т.к. их легко можно вырезать.
УСТРОЙСТВА ДЛЯ ЗАПИСИ ПО ПРИОРИТЕТУ:
1) - диктофон
2) - компьютер (необходимо наличие микрофона)
3) - ноутбук, планшет
4) - видео камера
5) - айфон, айпед и пр. ай)
6) - мобильный телефон
Шаг 2. – Запись.
Говорите чётко, громко, уверенно излучая позитив или эмоции соответствующие цели голосового послания.
Шаг 3. – Проверка.
После записи, обязательно прослушайте как звучит ваш голос. Возможно вы держали микрофон слишком близко (звук дребезжит) или слишком далеко (звук тихий). Экспериментируйте и не забывайте об УЛЫБКЕ!
Читайте также: